🪢 RoPE: Rotary Position Embedding
What is RoPE?
- A technique used to encode positional information of tokens in the input sequence of Transformer-based language models
- Essential for understanding the order and meaning of tokens in large language models (e.g. GPT-3, BERT, etc.)
- The self-attention mechanism used in Transformers does not inherently capture the positional information of tokens
Why is RoPE used?
-
Overcomes limitations of fixed and learned positional embeddings
- Fixed positional embeddings are predefined vectors that are added to the token embeddings at the input layer, encoding the position of each token in the sequence
- Learned positional embeddings are trainable vectors that are learned during the model training process, allowing the model to capture more complex positional patterns
- Efficiency: Saves memory usage and computation. It does not require storing or learning separate positional embeddings for each position in the sequence. This is particularly beneficial for long sequences or very large vocabularies
- Generalization: Can generalize to sequence lengths longer than those seen during training, as the sinusoidal encodings can be computed on-the-fly for any position. Fixed and learned positional embeddings are limited to the maximum sequence length seen during training
- Relative Positional Information: Can capture relative positional information between tokens, which is useful for tasks like machine translation or language generation, where the relative position of tokens is important
- Performance: Has shown improved performances on various natural language processing tasks, particularly for long sequences or tasks that require capturing long-range dependencies.
💡 Overall, RoPE is a more efficient and effective way of encoding positional information in large language models,
providing better generalization, capturing relative positional information, and improving model performance, especially
for long sequences or tasks that require capturing long-range dependencies.
How does RoPE work?
Steps in RoPE- Initialize Frequency Array: Array of frequencies initialized using an exponential scaling function. These frequencies serve as rotation factors
- Position-Based Scaling: Positions of tokens in the sequence are scaled by the frequency array. Scaled positions are used for rotating the embeddings (instead of addition)
- Construct Rotary Matrix: Rotary matrix created by stacking sine and cosine values of scaled angles. This matrix is used to rotate the original embeddings
- Rotate Embeddings: Rotary matrix reshaped to match the model's embedding dimension. Reshaped matrix multiplied with original query and key embeddings. Embeddings rotated based on their positions
- Variable Rotation Speed: Different dimensions in embeddings rotated at different speeds (determined by frequencies). Can be visualized as different clock hands rotating at distinct speeds
- Dot Product Significance: Embeddings rotated to similar angles have high dot product (indicating positional closeness). Dot product diminishes as relative distance increases (encoding relative positional information)
- Flexible Sequence Lengths: Can generalize to arbitrary sequence lengths by rotating embeddings accordingly (unlike fixed positional embeddings)
- Relative Position Encoding: Naturally incorporates relative position information into self-attention mechanism. Enables capturing dependencies between tokens based on their relative positions
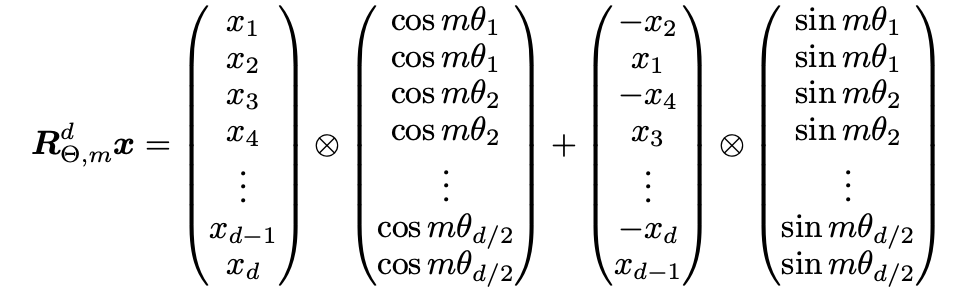
Conclusion
- Really enjoyed the paper: clear and rigorous mathematical proofs
"Despite the fact that we mathematically format the relative position relations as rotations under 2D sub-spaces,
there lacks of thorough explanations on why it converges faster than baseline models that incorporates other position
encoding strategies."
"Although we have proved that our model has favourable property of long-term decay for intern-token products,
which is similar to the existing position encoding mechanisms, our model shows superior performance on long texts
than peer models, we have not come up with a faithful explanation."