📺 ViTs: Visual Transformers
What are ViTs?
- An application of the Transformer architecture typically used for NLP to image recognition, i.e. image classification tasks
- ViTs achieve state-of-the-art performance when scaled
- ViTs are able to handle images of arbitrary size
- When trained on insufficient amount of data, Transformers lack some of the inductive biases inherent to CNNs, such as translation equivariance and locality, and therefore do not generalize well
- This changes if the models are trained on larger datasets (14M-300M images)
Model Details
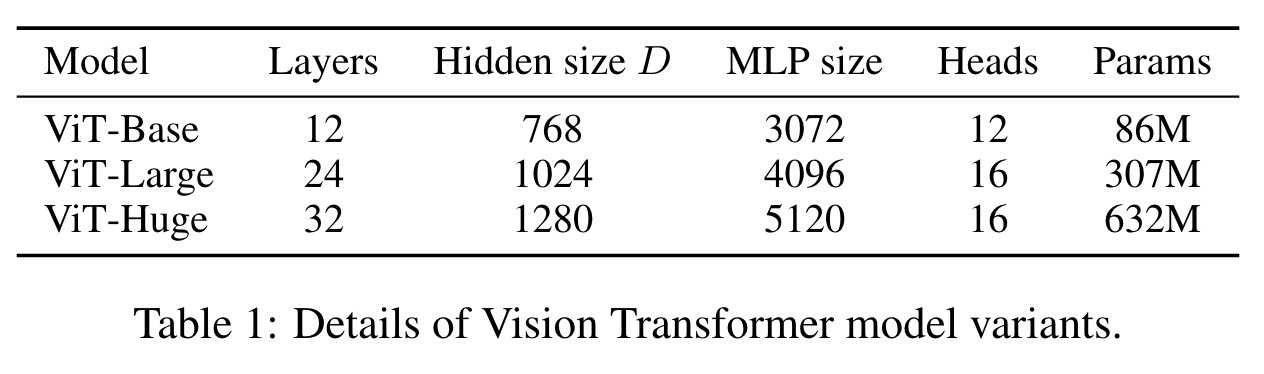
ViT-Large uses image patches of dimension 16 x 16
ViT-Huge uses image patches of dimension 14 x 14
Pretraining
- Adam: β1 = 0.9, β2 = 0.999
- Batch size = 4,096
- weight decay of 0.1
- linear learning rate warmup
- Image resolution: 224 x 224
Fine-tuning
- SGD with momentum of 0.9
- Batch size = 512
- Image resolution: 384 x 384
Forward Pass
- Images of shape
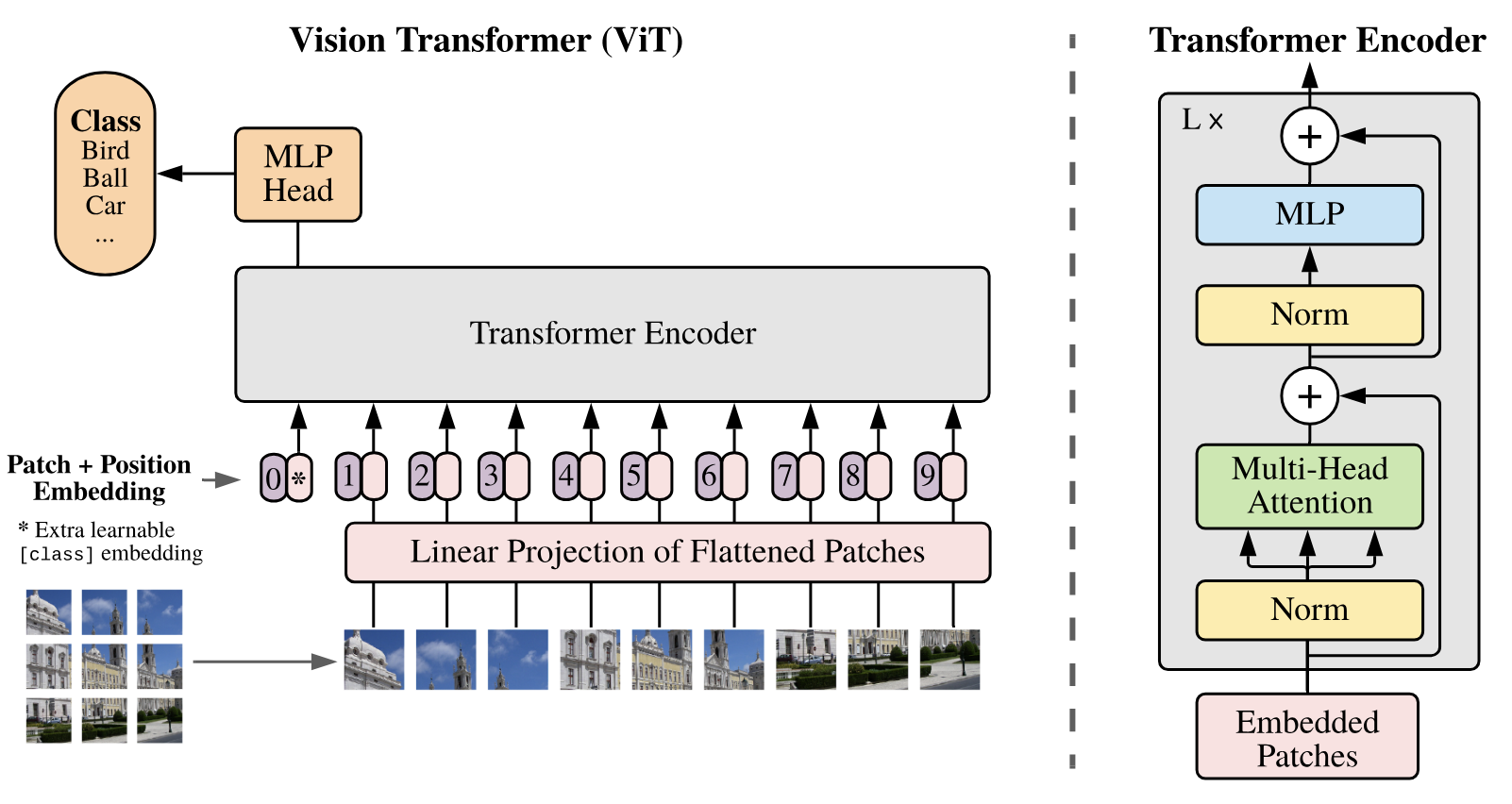
(H, W, C)are converted into a sequence of flattened 2D patches of shape(N, P^2*C) H= height,W= width,C= channels,P= side of patchN = HW/P^2is the resolution of an image (HW) divided by the size of a patch (P^2). This is equivalent to counting how many patches can fit into an imageNis also equivalent toseq_lenfor the Transformer architecture- Similar to BERT's
[CLASS]token, a learnable embedding is prepended to the sequence of embedded patches (as indicated by0*on the image above). It is randomly initialized and the same vector is used for all images - The output of the Transformer encoder for this position serves as the overall image representation and a classification head is attached to this position
- Position embeddings are added to the patch embeddings to retain positional information, similar to the use of Word Position Embeddings,
wpein the Transformer - The Linear Projection of flattened patches projects them into
d_model dimensions. This layer represents the patch embeddings (equivalent to a Word Token Embedding layer,wte, for the Transformer)
There are no modifications compared to the original Transformer forward pass
MSA = Multihead Self-Attention, LN = Layer Norm, z_0 represents the embedded patches + position embeddings,
D = d_model, L is the number of layers in the Transformer (layers are processed sequentially)
Pretraining vs Fine-tuning
- Typically, ViTs are pretrained on large datasets, and fine-tuned on smaller downstream tasks
- Pretraining is done using one prediction head, while fine-tuning is based on a zero-initialized
D x Kfeedforward layer, whereKis the number of downstream classes - Using images of higher resolution has been proven to be beneficial during fine-tuning. In this case, 2D interpolation of the pre-trained position embeddings are manually injected to balance for the loss of meaning of the pre-trained position embeddings (shorter sequence length seen during training)
- Standard cross-entropy loss function used during training to compare the predicted class probabilities with the true class labels
Results
- ViTs attain state of the art on most recognition benchmarks at a lower computational pre-training cost compared to ResNet (previous SOTA)
- Performances have shown to scale with model size and dataset size
- This result reinforces the intuition that the convolutional inductive bias is useful for smaller datasets, but for larger ones, learning the relevant patterns directly from data is sufficient, even beneficial
- The researchers noticed that pretraining efficiency seems dependent on training schedule, optimizer, weight decay, etc. though
- Vision Transformers overfit faster on smaller datasets than ResNet
- Vision Transformers dominate ResNets on the performance/compute trade-off
- ViT uses approximately 2 - 4x less compute to attain the same performance
- Vision Transformers appear not to saturate within the range studied, motivating future scaling efforts
- The researchers note that much of the Transformer model's success stems not only from their excellent scalability but also from their suitability to large scale self-supervised pre-training - that they would like to explore more in the future
💡 TL;DR: Vision Transformer matches or exceeds the state of the art on many image classification datasets, whilst being relatively cheap to pre-train
The researchers demonstrate the effectiveness of interpreting an image as a sequence of patches, processed similarly as in NLP tasks. They prove that this approach is scalable and effective coupled with pre-training on large datasets
The researchers demonstrate the effectiveness of interpreting an image as a sequence of patches, processed similarly as in NLP tasks. They prove that this approach is scalable and effective coupled with pre-training on large datasets
Next areas of research mentioned
- Research application of ViTs to other computer vision tasks, such as detection and segmentation
- Continue exploring self-supervised pre-training methods
- Further scale ViTs, as this would likely lead to improved performance